
How To Reduce eDiscovery Costs By Using A Digital Forensic Professional
- Oct 20, 2021
- 5 min read

According to Forbes, it was estimated that in 2020 approximately 1.7 megabytes of new information was created every passing second for every human on Earth. In 2015 they reported that more data was created globally within the two year span between 2013 and 2015 than in the entire recorded history of the human race. Hyperbole aside, it is safe to say that electronically stored information sizes have increased exponentially over the years as we as a species have become increasingly inseparable from the digital devices that we rely upon. Consequently due to their evidentiary value, our text messages, email conversations, Internet browsing histories, GPS locations, and other sources of digital information have evolved into becoming evidence items admissible in a court of law. In the legal services industry electronic discovery was initially born out of the need for legal professionals to be able to effectively sort and review large quantities of legal paper documents more efficiently. The introduction of eDiscovery processing software substantially reduced the level of human interaction required in the legal review process by automating historically humans tasks such as text indexing, OCR scanning, keyword searching, date filtering, as well as many others. These innovations in eDiscovery changed the legal services landscape by reducing the undesirable task of reviewing millions of legal paper documents into a much less arduous proposition. Eventually the field grew to accommodate processing the rapidly expanding volumes of digital evidence as it had previously done for paper. But while the eDiscovery costs associated with legal paper have leveled out and decreased over the years, the costs associated with processing the growing volumes of digital evidence have continued to increase, largely due to data ingestion charges.
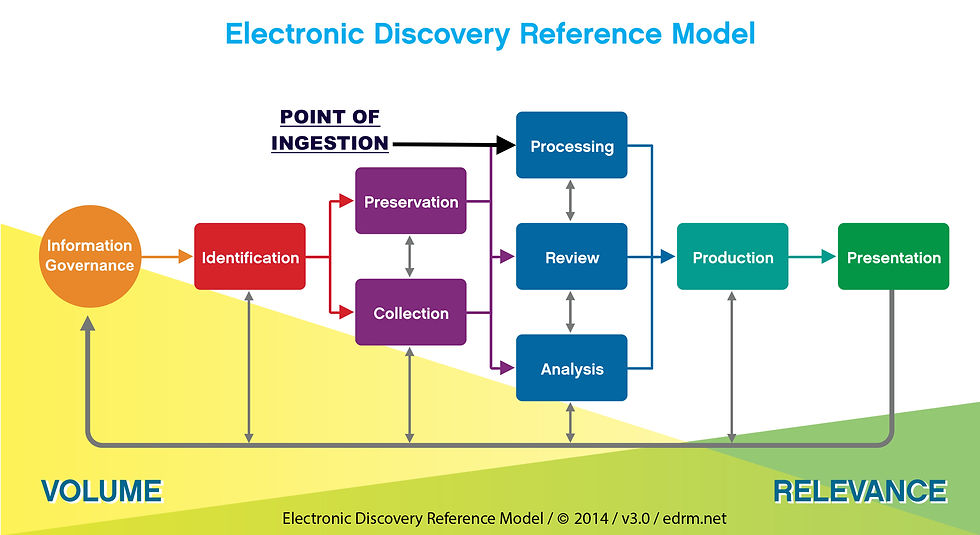
In eDiscovery terms, ingestion is the process in which data is imported into an automated tool for processing. As shown in the electronic discovery reference model displayed above, ingestion takes place after the desired data has been collected (hopefully by a digital forensic professional…more on that later), and it is the next step in preparing the data for hosted review. The challenge with managing ingestion costs when it comes to digital evidence is that the majority of vendors in the eDiscovery marketplace charge per gigabyte at the data ingestion stage of their workflow tracks. So if for example you have 100 GB of data, and your eDiscovery vendor charges $100 per gigabyte for data ingestion, then you will pay $10,000 in ingestion charges. But what happens when you have 100 GB of data in total but you suspect that only 10 GB of the data is actually relevant for your case? Should you really pay to ingest all 100 GB? If your answer is automatically yes then what this means for you is that your final bill will include fees associated with ingesting non-responsive data that adds zero evidentiary value to your case, but has the potential to add plenty of zeros to your eDiscovery vendors bottom line.

The value that a digital forensic professional can provide to you is in reducing the volume of collected data that enters into ingestion, which will have a direct correlation to your cost savings. Simply put, to save money on ingestion costs your goal should be to provide your eDiscovery vendor with the smallest dataset possible consisting of the highest attainable percentage of responsive data. For example, let’s now imagine that you have 250 GB of collected data consisting entirely of Windows system files, PDF files, Microsoft Excel Spreadsheets, and Microsoft Word Documents. In this hypothetical scenario let’s also pretend that you are only interested in reviewing the Microsoft Word documents and PDF files that were created by the custodian within a specific date range. If your eDiscovery vendor were to ingest this entire dataset as is at the rate of $75 per gigabyte then you will end up with an invoice for $18,750 in data ingestion charges. Another possible course of action for your eDiscovery vendor would be to reduce the volume of data by only ingesting the Microsoft Word Documents and PDF files. The problem with this option is that by moving all of the Word docs and PDF files forward to processing they will not be able to take your date range criteria into account until after ingestion. As a result you will still end up paying to ingest files that fall outside of the scope of your date range. The most cost-effective option in this scenario, and the course of action resulting in the greatest data reduction is to utilize a digital forensic professional in your eDiscovery workflow to forensically pre-cull out only the exact files that are responsive to your inclusionary criteria. The benefit of doing so means that you will then be able to confirm that every single file provided to your eDiscovery vendor is responsive to your case prior to ingestion. Adding this additional step for forensic pre-culling in your eDiscovery workflow as illustrated below will result in reducing your total data volume, subsequent total costs, as well as the time needed to process the responsive documents.

One question you may be asking is, “Can’t my eDiscovery vendors processing tools reduce my data sizes using keyword searching, de-duplication, date filtering, file extensions, etc.?” In short, absolutely. Your eDiscovery vendor’s processing tools can certainly identify the responsive Microsoft Word Documents and PDF files that are relevant to your case in our hypothetical scenario. The challenge is that they will need to ingest all of the data into their processing tools first to be able to isolate the responsive documents via your date range, which you will be charged for. Your next question might be, “Well why wouldn’t my eDiscovery vendor suggest ways to reduce my data sizes prior to ingestion so that I can save money?” In their defense, I tend to liken this situation to the trustworthy mechanic at my local auto dealership who neglects to mention that the expensive service that they are recommending I should pay them for can be easily done for a fraction of their price over at the new local auto shop in town. It’s just not usually conducive to their business models to advertise that there is a more cost-effective solution available around the corner.
The purpose of this article is not to paint with a broad brush suggesting that every eDiscovery vendor in the marketplace conducts business the same way. On the contrary, your eDiscovery vendor of choice might do a commendable job of informing you of all of your options in regards to reducing data sizes prior to ingestion. The goal of this article is to get you to think critically and to hopefully inspire you to ask the right questions before you receive that painful final bill. It is critical to highlight that when it comes to the complexities of managing digital evidence there are no one-size-fits-all solutions. Operating in terms of absolutes is dangerous, and every matter should be assessed on a case-by-case basis to determine what is the best way to proceed forward for that particular project. In the next segment we will take a deeper dive into exploring the pluses, minuses, and limitations of using a forensic professional to reduce data volumes via global or case level de-duplication, keyword searching, date filtering, file extension culling, as well as denisting. Thanks for reading! Please like, comment, and share liberally.
About the Author:
Nick Barlow is the founder and CEO of Beam Computer Forensics, LLC, which specializes in digital forensic collections, litigation support, and digital forensic analysis. The company is based out of Atlanta, GA.
www.BeamComputerForensics.com
References & Credits
Forbes: https://www.forbes.com/sites/bernardmarr/2015/09/30/big-data-20-mind-boggling-facts-everyone-must-read/#4f8abab417b1
EDRM: http://www.edrm.net/frameworks-and-standards/edrm-model/

Comments